PART II: AUDIO SIMILARITY
1. Summary of the specific audio features dataset you have chosen
The 'area of moments' dataset extracts statistical moments from audio signals, treating them as a 2- dimensional function, similar to how moments are used in image processing (Fujinaga, 1996). These moments capture essential characteristics of the audio, such as texture and distribution patterns. Hence, we chose this dataset because it provides a comprehensive summary of the signal's properties, which is particularly useful for tasks like audio classification (Ajoodha et al., 2015). The AOM dataset contain 994,623 rows and 21 columns. The first 20 columns are numeric and represent statistical summaries of the audio signal, with the first 10 columns capturing the standard deviation and the next 10 columns representing the average. The final column, "MSD_TRACKID” is a string type that uniquely identifies each track. Since this feature dataset have a long column name, in order to make it easy to interpret and visualize, we create a systematic way to rename columns as below:
| Original column name | Prefix column name |
|---|---|
| Area_Method_of_Moments_Overall_Standard_Deviation | AMM_std_1 to AMM_std_10 |
| Area_Method_of_Moments_Overall_Average | AMM_avg_1 to AMM_avg_10 |
2. Generate the descriptive statistics for each audio features
2.1 Descriptive statistics
Before performing the descriptive statistics, it is important to check for missing values as they can affect the accuracy of the results. By using the “isNull()” function, we found 19 missing values in columns “AMM_avg_3” to “AMM_avg20”. Since this is a small portion of the overall data, we drop these rows to ensure a cleaner analysis. Moreover, we also drop the "MSD_TRACKID” as it is the track id column which shown no meaning in the descriptive statistics. The “describe()” function is used to perform a descriptive statistics and the result had been converted to Pandas dataframe with transposed the feature into rows for easy observe as there are too many columns.
| Feature | Count | Mean | Std Dev | Min | Max |
|---|---|---|---|---|---|
| AMM_std_1 | 994604 | 1.22892124 | 0.528240504 | 0 | 9.346 |
| AMM_std_2 | 994604 | 5500.56839 | 2366.029717 | 0 | 46860 |
| AMM_std_3 | 994604 | 33817.8867 | 18228.64684 | 0 | 699400 |
| AMM_std_4 | 994604 | 1.28E+08 | 2.40E+08 | 0 | 7.86E+09 |
| AMM_std_5 | 994604 | 7.83E+08 | 1.58E+09 | 0 | 8.12E+10 |
| AMM_std_6 | 994604 | 5.25E+09 | 1.22E+10 | 0 | 1.45E+12 |
| AMM_std_7 | 994604 | 7.77E+12 | 5.69E+13 | 0 | 2.43E+15 |
| AMM_std_8 | 994604 | 7.04E+09 | 7.46E+11 | 0 | 7.46E+11 |
| AMM_std_9 | 994604 | 4.72E+10 | 1.10E+11 | 0 | 1.31E+13 |
| AMM_std_10 | 994604 | 2.32E+15 | 2.46E+16 | 0 | 5.82E+18 |
| AMM_avg_1 | 994604 | 3.51675685 | 1.860093501 | 0 | 26.52 |
| AMM_avg_2 | 994604 | 9476.01684 | 4088.523898 | 0 | 81350 |
| AMM_avg_3 | 994604 | 58331.7023 | 31372.66477 | 0 | 1003000 |
| AMM_avg_4 | 994604 | -1.42E+08 | 2.67E+08 | -8.80E+09 | 0 |
| AMM_avg_5 | 994604 | -8.73E+08 | 1.76E+09 | -9.01E+10 | 0 |
| AMM_avg_6 | 994604 | -5.86E+09 | 1.36E+10 | -1.50E+12 | 0 |
| AMM_avg_7 | 994604 | 6.84E+12 | 1.22E+11 | 0 | 2.14E+15 |
| AMM_avg_8 | 994604 | 7.83E+09 | 1.58E+10 | 0 | 8.34E+11 |
| AMM_avg_9 | 994604 | 5.26E+11 | 1.22E+11 | 0 | 1.35E+13 |
| AMM_avg_10 | 994604 | 2.04E+15 | 2.16E+16 | 0 | 4.96E+18 |
The descriptive statistics shown all features have the same number of counts, with the minimum value at “AMM_avg_5” and maximum value at “AMM_avg_8”. The mean and standard deviation show varying ranges across feature, with some low value to extremely high of variability. This mean that some features show a wider range of value which is easy to capture the different between songs in different genres. On the other hand, several features with low variability might not useful as they do not show many meaningful across different genres. Hence, the model might become bias as it had been dominating by the high variability features. Furthermore, when it comes to logistic regression, we can use the size of coefficients as a proxy for feature important, but only when the features have the same mean and standard deviation. If one feature has a much larger scale than other features, the coefficient can be really small and have a big impact in overall model. Hence, if we want to interpret the coefficient of the features, we should take the scale of features into account. As a result, feature scaling (e.g normalization) can be used to make all features contribute equally when it comes to training model.
2.2 How features distributed?
In order to know how the features are distributed, the histogram shown the distributed of each feature between mean and standard deviation had been generated (see Appendix C). According to the histogram, it appears that several features have a similar distribution, particularly between standard deviation and average columns. For example, “AMM_std_5” to “AMM_std_10” and “AMM_avg_5” to AMM_avg_10” share the same distribution as it heavily skewed towards the small values with most of data concentrate near zero. On the other hand, the “AMM_std_1”, “AMM_std_3” and “AMM_avg_1”, “AMM_avg_3” show the variation compared to the others but it still appears some skewness. Since features are distributed similarly, they may contribute less to distinguishing between classes lead because it provides redundancy information where features do not add new information for the model. Hence, the model might be struggled to identify the patterns between features and the target variables.
2.3 Features Correlation
To identify any features are correlated, the correlation matrix had been performed to calculate the correlation between each feature. The “VectorAssembler()” used to transform PySpark dataframe into vectors, the feature name now had transform to the vector as 0 to 19, represent 20 feature columns respectively. The Correlation function in “PySpark.ml” was used to perform the correlation matrix (Ayan, 2024). In order to make it easy to read and interpret we transform it into Pandas dataframe and perform a heatmap as below:
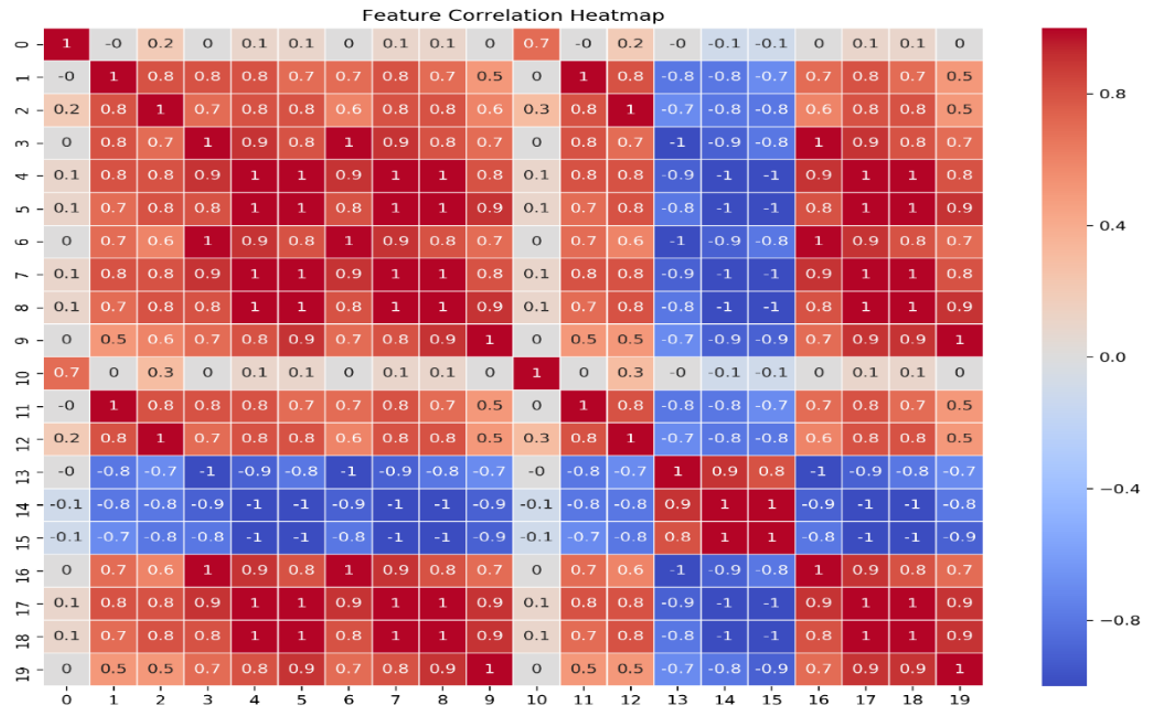
The heatmap shows the pairwise correlations between different features in the MOA dataset. Features with correlations close to 1 (deep red) are strongly positively correlated. For example, feature 5 and feature 19 are strongly correlated (0.9), these features might share the similar patterns. Features with correlations close to -1 (deep blue) are strongly negatively correlated. For example, feature 13 and feature 14 are perfectly negative correlated with a value of -1. Correlations close to 0 indicate a little to no linear relationship between them. Notice that feature 10 only have the high correlation with feature 0 and seem to be very low to no correlation between other features. Moreover, based on the heatmap we can observe that there are many features that perfectly correlated need to be taken into account. In order observe it more detail, we group all the feature pairs that exactly perfect correlated and assign the column names instead of showing the vector number (appendix D). There are 16 features that perfectly correlated with the corelation score of 1 and -1 which is also called the perfect multicollinearity. This might be a potential problem if we include all the features into the model as it will violate the assumption of linear model that independent variables are not perfectly correlated. When independent variables are correlated, the changes in one variable are associated with shifts in another variable, this mean that the stronger the correlation is the more difficult for the model to estimate the relationship between each independent and dependent variable independently (Frost, 2017). According to (Frost,2017), there are some potential solutions to dealing with the multicollinearity such as remove highly correlated features or using Lasso and Ridge regression to shrink the multicollinearity feature less impact to the model. Hence, in this assignment, due to time constraint, we used regularization method to deal with those high correlated features, if we have more time, it also good to deep dive into each feature and explore how it related to genre classification.
3. Load the MSD Allmusic Genre Dataset (MAGD) & Visualize the distribution of genres
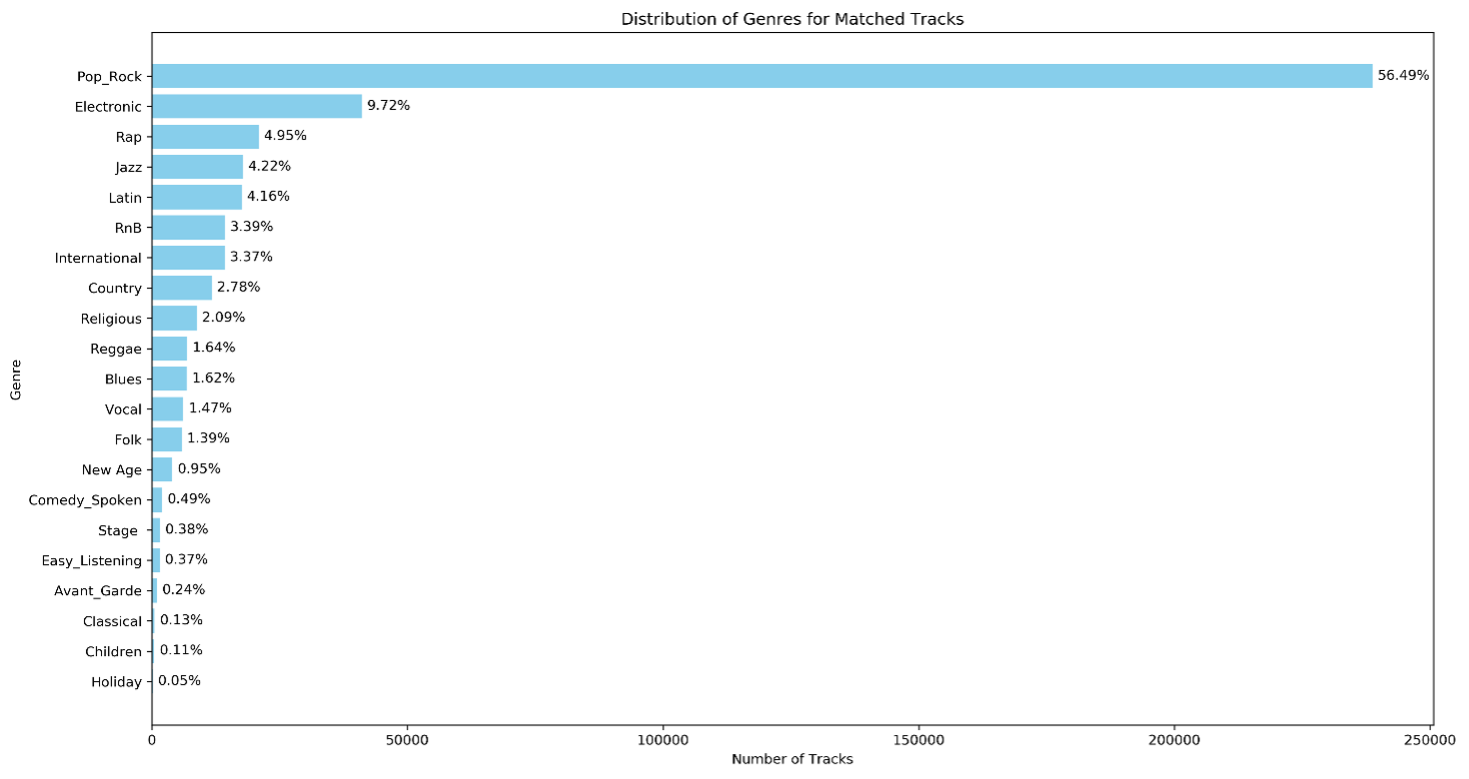
In order to load the MSD Genre dataset, we first define the schema and load the msd-MAGD- genreAssignment.tsv file from HDFS into a Spark DataFrame called MAGD_genre_data. This dataset contains two columns: track_id and the corresponding genre for each song. According to MAGD_genre_data, there are 422,714 tracks with genre information. To visualize the distribution of genres for the tracks that were matched with the audio features, we perform an inner join between MAGD_genre_data and the AOM features dataset using the MSD_TRACKID. This inner join ensures only tracks with both genre and feature data are included. After the join, the resulting dataset, songs_with_genre, is used to visualize the genre distribution and ready for further analysis.
The genre distribution in this dataset reveals a clear imbalance, with Pop_Rock dominating over 56% of the tracks, while smaller genres like Holiday, Children and Classical each make up less than 1%. This uneven distribution can significantly affect the performance of a machine learning model. For example, if we want to predict the Electronic genre, which makes up less than 10% of the total tracks, the model might struggle because it is biased toward predicting dominant genre (Pop_Rock). Even if the model misclassifies most Electronic genre as Pop_Rock, it could still achieve high overall accuracy due to imbalance. However, this would not be useful if our goal is to accurately identify Electronic tracks. In this scenario, the accuracy metric becomes misleading as it does not provide a true measure of the model ability to detect the less common Electronic genre, leading to poor performance in the areas where its matters most.
4. A brief summary of each of algorithms has been chosen
In order to address this classification task, we choose 3 classification algorithms which is Logistic Regression, Random Forest and Gradient Boosted Tree. Logistic Regression (LR) is a linear model, which means it has a relatively simple mathematical structure, leading to fast training speed. It provides coefficients for each feature which represent the strength of and direction of the relationship between feature and target. Due to its high explainability and interpretability, LR is often used as a baseline model. However, it can easily overfit since there are highly correlated features in the AOM dataset as it might give too much weight to redundant information. To address this, regularization techniques such as L1 (Lasso) and L2 (Ridge) will be used to shrink the coefficient of redundant features. Moreover, when perform the regularization, it is sensitive to feature scaling since the penalty will treat features as same scale. According to descriptive statistics, there are huge differences in the range between each feature, it is important to apply scaling method to scale all features to a similar range. Random Forest is an ensemble learning method that builds multiple decision trees and combines them to produce more accurate and stable predictions. It is well suited for handing complex datasets and can handle non linear data and high dimensionality without require data scaling or regularization as it will pick the most important feature to perform a split. However, due to its complexity when building multiple trees, it had slow training speed compared to linear models and also difficult to interpret since it requires some hyperparameter tuning such as number of trees and depth of trees. Gradient Boosted Trees (GBT) is an ensemble learning method that builds a series of decision trees where each subsequent tree corrects the errors of the previous one. This sequential training makes GBT highly accurate and effective at handling both linear and non linear relationships. However, similar to RF, GBT involves many decision trees, making it difficult to understand how the model predicts. It also easy prone to overfitting and huge computational time as it requires many hypermeters tunning.
| Logistic Regression | Random Forest | Gradient Boosted Trees | |
|---|---|---|---|
| Explainability | High | Low | Low |
| Interpretability | High | Low | Low |
| Predictive Accuracy | Moderate | High | High |
| Training Speed | Fast | Slow | Slow |
| Hyperparameter Tuning | Minimal (L1 & L2) | High | High |
| Scaling Requirement | Required | Not required | Not required |
5. A brief statement of class imbalance and how it affects model.
To convert the genre column into a new binary label the represent Electronic genre and other genre, a new columns called “class” is created with filter if the genre is Electronic than assign the value 1 and otherwise is 0 for other genre using the “F.when” function. By count the number of songs in each class (0 and 1) and calculate the percentage, the class imbalance of a binary model shown as below:
| Class | N.o of songs | Percentage |
|---|---|---|
| Electronic (1) | 40,662 | 9.67% |
| Non - Electronic (0) | 379,942 | 90.33% |
| Total | 420,604 | 100% |
According to table 5, there is a highly imbalanced between Electronic and Non Electronic genre, with approximately 9.67% of the tracks labelled as Electronic and 90.33% are Non Electronic. This imbalance can negatively affect the performance of the classification model. Specifically, the model may become biased toward the majority class, predicting more often due to the larger number of samples. This could create a high accuracy but fail to correctly predict the minority class and could lead to poor performance as our goal is trying to identify the minority Electronic tracks.
6. Explanation of stratify random split and resampling methods
Since there is an extreme class imbalance in the dataset, we apply stratified sampling when performing the train – test split to ensure class balance is preserved. We start by generating a unique ID column, which will allow us to an anti - join later. Next, we create a random column containing random numbers for each row. After that, we generate a new column for row numbers using the window function, evaluated over the window to give row numbers for each class. The window specification is used to partition by our label and order it randomly. Once we have the row numbers, we then define a filter, for label 0 (Electronic) we keep the row if its row number is less than the number of classes 1 (Non – Electronic) rows multiplied by a specific proportion (0.8). Finally, we perform anti join using the ID column generated earlier to obtain the test set, then we drop irrelevant columns. By doing this, we ensure that the class proportion in both training and test sets mirror the original data distribution. The class balance is maintained across both sets, preventing further imbalance. This approach provides consistent class ratios even when running multiple random splits, allowing us to generate reliable precision and recall metrics for test data. The table below show the rows and ratio for training and test. Since our data have a high imbalanced class, before fitting it to the model we want to potentially change this classes proportion in the training data, so the model is more sensitive to our target genre (Electronic). Our goal is trying 4 different types of resampling methods with 3 different models (mentioned above) to determine which yield the best performance. Firstly, we use the oversampling where we are randomly upsample observations of rare classes. The key ideas are keeping the same number of class 0 while upgrade more class 1 which a specific ratio. This might increase the sensitivity without throw away any values. Secondly, instead of creating more class 1 sample, we aim to fewer down class 0 to get a balance proportion between 2 classes. Thirdly, we try to combine both up and down sampling with setting the lower bound and upper bound, this approach seems to be more advance as it changing 2 classes at the same time ensuring both contribute to the class balance. Finally, instead of changing the actual rows, we simply weight the portion of those observations invert to their frequency. For example, in our case we will give the class 1 large weight and underweight for class 0. This allows the training method (e.g SGD) to update the learning rate effectively when it comes across the class 1 and 0. The table below shown the ratio of each resampling methods.
| Class Label | No Sampling | Down Sampling | Up Sampling | ReSampling | Reweighting | ||||
|---|---|---|---|---|---|---|---|---|---|
| Count | Ratio (%) | Count | Ratio (%) | Count | Ratio (%) | Count | Ratio (%) | Weight | |
| Electronic Genre (1) | 32529 | 0.09667 | 32529 | 0.333248 | 50167 | 0.1451 | 49921 | 0.27391 | 5 |
| Other Genre (0) | 303953 | 0.90333 | 65083 | 0.666752 | 296036 | 0.85624 | 131496 | 0.72149 | 0.5 |
| Total | 336482 | 97612 | 346203 | 181417 | |||||
7. Train models and evaluate on test set.
For LR model, we have used 10% from the training dataset to do the 5 - folds cross validation to find the best lambda for regularization. Surprisingly, after 5 folds validation no regularization yield the best AUROC, moreover, we also compare the performance between regularization and non regularization, however, the non regularization yield the best performance over the test set over all sampling methods. After resampling three models had been used to train and evaluate the metrics on the test set as below:
| Models | Sampling Methods | Performance Metrics | |||
|---|---|---|---|---|---|
| Accuracy | Precision | Recall | AUROC | ||
| Logistic Regression | No Sampling | 0.9032 | 0.4217 | 0.004303 | 0.6303 |
| UpSampling | 0.9030 | 0.3810 | 0.005902 | 0.6307 | |
| ReSampling (up/down) | 0.9001 | 0.3210 | 0.029878 | 0.6330 | |
| DownSampling | 0.8935 | 0.2851 | 0.067380 | 0.6324 | |
| Observation Reweighted | 0.8856 | 0.2534 | 0.094184 | 0.6327 | |
| Random Forest | No Sampling | 0.9033 | 0.5590 | 0.000369 | 0.6656 |
| UpSampling | 0.9032 | 0.5294 | 0.027665 | 0.6643 | |
| ReSampling (up/down) | 0.9032 | 0.4921 | 0.026804 | 0.6669 | |
| Down Sampling | 0.8751 | 0.2825 | 0.189475 | 0.6812 | |
| Observation Reweighted | 0.8668 | 0.2683 | 0.218493 | 0.6804 | |
| Gradient Boosted Tree | No Sampling | 0.9036 | 0.5512 | 0.017214 | 0.7123 |
| UpSampling | 0.9036 | 0.5205 | 0.032829 | 0.7092 | |
| ReSampling (up/down) | 0.9038 | 0.5459 | 0.027050 | 0.7129 | |
| Down Sampling | 0.8564 | 0.2683 | 0.280708 | 0.7174 | |
| Observation Reweighted | 0.8562 | 0.2693 | 0.284643 | 0.7175 | |
When comparing the different models, AUROC is a suitable as it is based on changing classification thresholds and observing how our true positive and false positive rate trade off each other. Therefore, it is independent on the classification threshold, allows AUROC capturing the overall effective. Based on Table 6, resampling methods significantly improve recall compared to the original models, indicating that these methods help address class imbalance by making the model more sensitive to the minority class. In LR model, while observation reweighting achieves the highest recall, the resampling method provides the highest AUROC. Similarly, for Random Forest, reweighting achieves higher recall, but down sampling yields the best AUROC, making it the most balanced option for this algorithm. Notably, the Gradient Boosted Tree (GBT) model achieves the highest AUROC (0.7175), suggesting it has the strongest ability to distinguish between the Electronic and Non-Electronic classes. Therefore, if the goal is to maximize the ability to distinguish between the two classes, the GBT model with observation reweighting is the best choice due to its highest AUROC.
8. Explanation of how chosen algorithm predict mutiple classes
There are multiple algorithms can be chosen to perform the multiple classification, however, in this assignment, we choose the Logistic Regression (LR) algorithm from “ml.pyspark” to perform the multiple classification for two reasons. First, in spark.ml logistic regression natively supports the multiple classes classification by using multinomial logistic regression with the “family” parameter as it provides a probability across multiple classes (Spark 3.5.3 Documentation, n.d.). Secondly, as mentioned above, LR model have the fast-training speed compared to other models like RF and GBT, due to the time constraint for this assignment, we also choose LR model for time efficiency.
How classes imbalance effect the result?
When transitioning from binary classification to multiclass classification, the class imbalance has changed significantly. In binary case, we only needed to distinguish between two classes with 40, 662 tracks labeled as Electronic, and the rest is grouped into Non Electronic category. However, in the multiclass scenario, it much more diverse distribution across 21 genres with “Pop_Rock” dominating at 237,641 tracks while genre like “Holiday” and “Children” are highly underrepresented with only 200 and 463 tracks respectively. Since our target is trying to have a reasonably balance performance across genres. Therefore, resampling methods was taken into account here since several genre have a very low count which make the model struggle to classify these classes.
9. Stratified random split and resampling method
Similar to binary classification, we apply stratified sampling to ensure class balance is preserved. The strategy remains the same as in binary classification, however, instead of splitting two classes, we now split multiple classes while ensuring that each class maintains the same ratio in both the training and test sets. After performing the split, in order to a reasonably balance performance between classes, we perform the resampling method which include up sampling for minority class and down sampling for majority, making it more balanced together. However, we also do not want to make it perfectly balance as in real life there is also a wide distribution between each genre. Therefore, we create the lower bound and upper bound by defined the average class count where we take number of rows divided by the number of classes. For the overrepresentation genres we down sampling it to the upper bound which might less improve model performance but improve the training efficiency and for the underrepresentation genres we want to up sampling to within lower bound.
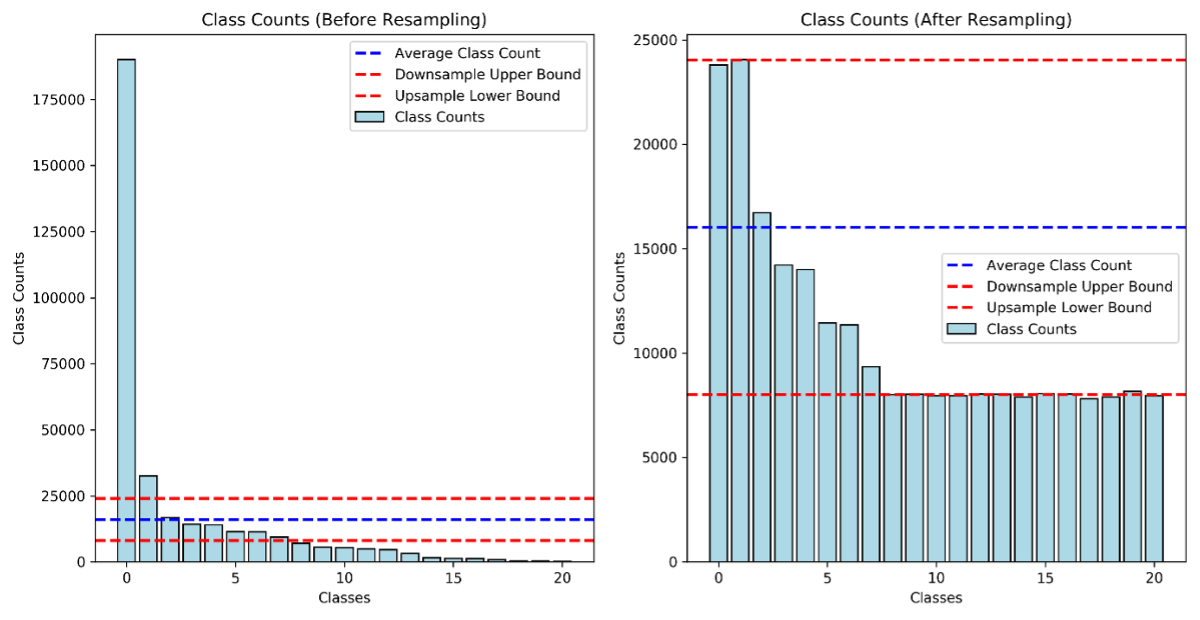
10. Evaluate multiclass classification performance metric
After resampling the training dataset and make all classes more balanced, we trained Logistic Regression model using multinomial classification to predict all genres. As there are multiple classes, we used the weight metrics such a precision, recall and f1 score to evaluate the performance.
| Model | Weight Precision | Weight Recall | Weighted F1 Score |
|---|---|---|---|
| Multinomial Logistic Regression | 0.454 | 0.363 | 0.393 |
As shown in the table 8, the very low performance metrics across all table, indicate that predicting multiple classes even harder than the binary once especially when there is significant class imbalance. The weight precision 0.454 indicating on overage across all classes 45.4% of the model’s positive predictions were correct. A weighted recall of 0.363 emphasizes only 36.3% the model correctly predicts the actual positive instances. The weighted F1 Score of 0.393 suggests that the model performance in both precision and recall is relatively low, highlighting the trade – off between them. Since precision is calculated as True Positives over predicted positives, when dealing with more than two classes, we weight each class's precision by the proportion of actual positives for that class relative to the total. However, in cases of class imbalance, weighted precision and recall can be heavily biased toward the majority (often negative) class. For example, the model could have 0 precision for a minority class like 'Holiday' but still achieve a high weighted precision due to performing well on the majority class like 'Pop_Rock', similar to how accuracy can be misleading. This means that weighted precision and recall can hide important details about per-class performance. To fully understand the model’s behaviour, it is crucial to examine precision and recall for each class individually.
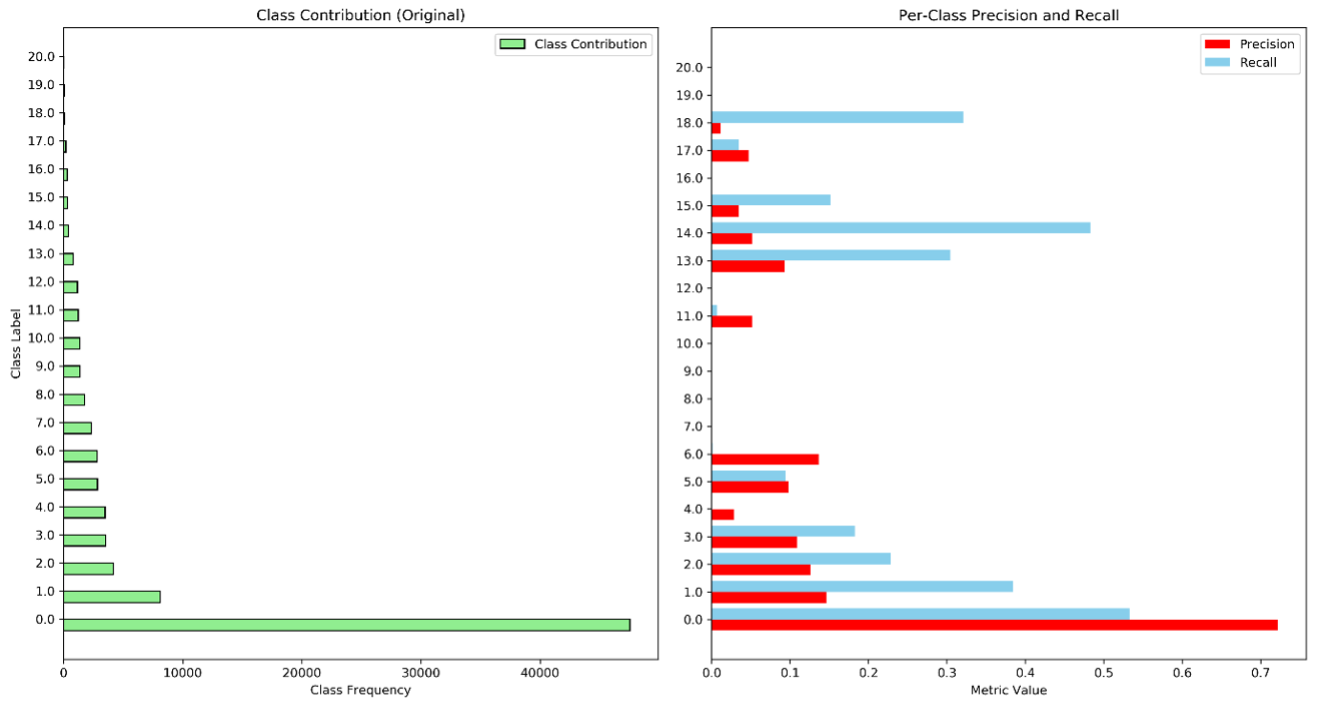
Based on figure 3, there is no surprise that class 0 and 1 have a largest precision and recall across all genre as they have a dominant distribution compared other. Although we already resample the minority classes such as 7,8,9,10,12,19, 20, they also perform not too good in precision and recall, this might because it only create a duplicate value when upsampling which introduce to noise. On the other hand, some of minority class (13,14,15,17,18) have improve the precision and recall after we upsampling it even though it consider as rare classes. As a result, by looking at precision and recall per class and compare it to their original distribution, we can understand how these metrics performed ans why it perform good or bad. Moreover, if we were interested in a particular rare class, we can possibly weight it more in our training.